import pandas as pd
import numpy as np
import yfinance as yf
from sentence_transformers import SentenceTransformer
from sklearn.decomposition import PCA
from sklearn.metrics import accuracy_score
from lightgbm import LGBMClassifier用 LLM 預測時間序列,可能嗎?
LLM
python
time series
摘要
觀察 LLM 應用於時間序列預測的各項應用。
緣起
之前看到一個2024年的討論,討論大型語言模型( LLM )應用在時間序列的實用度,下面的留言有些真的很有趣。像是
I am surprised that people even bother to benchmark this. We all know it is bs.
我很驚訝人們居然想做這個,我們都知道這是 bul sht。
There will be a list of papers with “Are LLM actually useful for x”, but answers are surely NO.
未來將會出現一堆標題為「LLM 對於某個領域真的有用嗎?」的論文,但答案肯定為否。
本文直接原地中槍
不過近年來大型語言模型延伸應用到許多地方,其中也包含時間序列的預測。我第一次看到是在Forecasting: Principles and Practice, the Pythonic Way,這本書的 R 語言版本在時間序列領域中很有名,我想這個議題應該是有引起一部份研究時間序列的學者注意。另外,用 LLM 預測時間序列,這個構想我覺得滿有趣的,趁有點時間來探討一下。
為什麼會想用 LLM 預測時間序列
LLM 顧名思義是用在文字上的模型,也就是用途生成最有可能文字或是句子,可是居然有人想用在預測時間序列上,為什麼? 要回答這個問題,我想先從 LLM 背後最主要使用的模型架構 Transformer 開始談起。
Transformer
與 RNN 和 LSTM 不同,Transformer 的模型架構多了 Encoding 、 Decoding 以及 Attention 的架構,而且不具備”一定要有上一筆資料才能預測下一筆”的特性。先來用一點數學式說明在 Transformer 裡 input 到 output 中間經歷了甚麼。
https://arxiv.org/pdf/1706.03762
整體而言,input 在經過 Transformer 的流程產出 output 的流程像這樣
- Embedding
將 input 轉成帶有距離意義的向量,可以想像成一些點散布在 X Y 的平面上,越靠近彼此的點越相似,並且這是絕對位置。
- Positional Encoding
這個步驟的目的是要把 input 的位置編碼,以便傳遞相對位置資訊給模型。在最早的論文裡用了 sin 與 cos 函數。
\[ PE(pos, 2i) = \sin\left(\frac{pos}{10000^{2i/d_{model}}}\right) \] \[ PE(pos, 2i+1) = \cos\left(\frac{pos}{10000^{2i/d_{model}}}\right) \]
其中 \(pos\) 表示位置,\(i\) 表示 input 裡的元素相對位置維度,\(d_{model}\) 表示 embedding 後的維度。
在此例裡,Positional Encoding的每一個維度都對應到一個正弦波。其波長從 \(2\pi\) 到 \(10000 \cdot 2\pi\) 呈幾何級數變化。
使用後會產生與 embedding 相同維度的向量,並且加入 embedding 後的同維向量裡。
- 多頭注意力機制(Multi-Head Attention)
令做完 embedding 與 positional Encoding 後的向量為 \(X\),把 input 分成查詢(Query, \(Q\))、鍵(Key, \(K\))跟值(Value, \(V\))的矩陣形式,則
\[ Q = X W^Q,\quad K = X W^K,\quad V = X W^V \]
這裡的\(W\)是權重矩陣,它的直觀意義為
| 符號 | 作用 |
|---|---|
| \(W^Q\) | 把輸入變成 Query |
| \(W^K\) | 把輸入變成 Key |
| \(W^V\) | 把輸入變成 Value |
這樣就可以組成一個代表注意力機制的函數\(\text{Attention}(\cdot)\)
\[ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V \]
其中\(d_k\) 是鍵矩陣(\(K\))的 columns 數,其實是可指定的定值,用來固定\(Q\) \(K\) \(V\) 的維度。這是因為實務上 key 值需要滿足 unique 、不得重複出現的性質,因此會依照需求自行設定。
注意力機制相當於賦予 input 權重,讓模型知道要把哪些東西納入預測考量。而多頭注意力機制則是注意力機制的強化版,顧名思義裡面會有好幾個 head,每一個 head 代表執行一次注意力機制的結果。
\[ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, ..., \text{head}_h) W^O \]
其中: \[ \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) \]
這裡的投影矩陣為:
- \(W_i^Q \in \mathbb{R}^{d_{model} \times d_k}\)
- \(W_i^K \in \mathbb{R}^{d_{model} \times d_k}\)
- \(W_i^V \in \mathbb{R}^{d_{model} \times d_v}\)
- \(W^O \in \mathbb{R}^{h d_v \times d_{model}}\)
| 符號 | 作用 |
|---|---|
| \(W_i^Q, W_i^K, W_i^V\) | 每個 head 各自的投影 |
| \(W^O\) | 把所有 head 融合回模型輸出 |
最後結果會丟入一個 FNN 裡,完成 Econding 的流程。
TimeGPT
另一個方向:將文字資訊納入預測考量
分類問題:用一個簡單的例子來實作
https://machinelearningmastery.com/can-llm-embeddings-improve-time-series-forecasting-a-practical-feature-engineering-approach/
利用道瓊指數相關新聞預測道瓊指數的收盤價是否下跌。
ticker = "^DJI"
df_price = yf.download(ticker, start="2008-01-01", end="2016-12-31",auto_adjust=False)
df_price = df_price[["Close"]]
df_price["return"] = df_price["Close"].pct_change()
df_price["target"] = (df_price["return"].shift(-1) > 0).astype(int)
df_price = df_price.dropna()
df_price.head()
# Adding lagged and rolling average features
for lag in [1, 2, 3, 5]:
df_price[f"lag_{lag}"] = df_price["return"].shift(lag)
df_price["roll_mean_5"] = df_price["return"].rolling(5).mean()
df_price["roll_std_5"] = df_price["return"].rolling(5).std()
df_price = df_price.dropna()/tmp/ipykernel_9407/3845017597.py:2: FutureWarning: YF.download() has changed argument auto_adjust default to True
df_price = yf.download(ticker, start="2008-01-01", end="2016-12-31")
[*********************100%***********************] 1 of 1 completeddf_news = pd.read_csv(
"https://raw.githubusercontent.com/gakudo-ai/open-datasets/refs/heads/main/Combined_News_DJIA.csv"
)
df_news.columns = df_news.columns.str.strip()
df_news["Date"] = pd.to_datetime(df_news["Date"], dayfirst=True)
headline_cols = [c for c in df_news.columns if c.startswith("Top")]
df_news[headline_cols] = df_news[headline_cols].fillna("")
df_news["combined"] = df_news[headline_cols].apply(
lambda row: " ".join([str(x) for x in row if str(x).strip() != ""]),
axis=1
)
df_news["combined"].head()| combined | |
|---|---|
| 0 | b"Georgia 'downs two Russian warplanes' as cou... |
| 1 | b'Why wont America and Nato help us? If they w... |
| 2 | b'Remember that adorable 9-year-old who sang a... |
| 3 | b' U.S. refuses Israel weapons to attack Iran:... |
| 4 | b'All the experts admit that we should legalis... |
import ast
def clean_bytes_text(x):
"""
Convert byte-like strings (b'...') to normal text
"""
if isinstance(x, str):
try:
evaluated_value = ast.literal_eval(x)
if isinstance(evaluated_value, bytes):
return evaluated_value.decode('utf-8')
else:
return str(evaluated_value)
except (ValueError, SyntaxError):
if x.startswith("b"):
return x.strip("b'\"")
return x
return x
df_news["combined"] = df_news["combined"].apply(clean_bytes_text)model = SentenceTransformer("all-MiniLM-L6-v2")
embeddings = model.encode(
df_news["combined"].tolist(),
show_progress_bar=True
)/usr/local/lib/python3.12/dist-packages/huggingface_hub/utils/_auth.py:93: UserWarning:
The secret `HF_TOKEN` does not exist in your Colab secrets.
To authenticate with the Hugging Face Hub, create a token in your settings tab (https://huggingface.co/settings/tokens), set it as secret in your Google Colab and restart your session.
You will be able to reuse this secret in all of your notebooks.
Please note that authentication is recommended but still optional to access public models or datasets.
warnings.warn(
Warning: You are sending unauthenticated requests to the HF Hub. Please set a HF_TOKEN to enable higher rate limits and faster downloads.
WARNING:huggingface_hub.utils._http:Warning: You are sending unauthenticated requests to the HF Hub. Please set a HF_TOKEN to enable higher rate limits and faster downloads.BertModel LOAD REPORT from: sentence-transformers/all-MiniLM-L6-v2
Key | Status | |
------------------------+------------+--+-
embeddings.position_ids | UNEXPECTED | |
Notes:
- UNEXPECTED :can be ignored when loading from different task/architecture; not ok if you expect identical arch.model = SentenceTransformer("all-MiniLM-L6-v2")
embeddings = model.encode(
df_news["combined"].tolist(),
show_progress_bar=True
)BertModel LOAD REPORT from: sentence-transformers/all-MiniLM-L6-v2
Key | Status | |
------------------------+------------+--+-
embeddings.position_ids | UNEXPECTED | |
Notes:
- UNEXPECTED :can be ignored when loading from different task/architecture; not ok if you expect identical arch.pca = PCA(n_components=20)
embeddings_reduced = pca.fit_transform(embeddings)
emb_df = pd.DataFrame(
embeddings_reduced,
index=df_news["Date"],
columns=[f"emb_{i}" for i in range(20)]
)emb_df = emb_df.copy()
emb_df.reset_index(inplace=True)
emb_df.rename(columns={emb_df.columns[0]: "Date"}, inplace=True)
if 'level_0' in df_price.columns:
df_price = df_price.drop(columns=['level_0'])
if 'index' in df_price.columns:
df_price = df_price.drop(columns=['index'])
df_price_cleaned = df_price.reset_index()
if isinstance(df_price_cleaned.columns, pd.MultiIndex):
new_cols = []
for col in df_price_cleaned.columns:
if col[0] == 'Date':
new_cols.append('Date')
elif isinstance(col, tuple) and col[1] != '':
new_cols.append(col[1])
else:
new_cols.append(col[0])
df_price_cleaned.columns = new_cols
if 'Ticker' in df_price_cleaned.columns:
df_price_cleaned = df_price_cleaned.drop(columns=['Ticker'])
df_price_cleaned['Date'] = pd.to_datetime(df_price_cleaned['Date'])
df = pd.merge(df_price_cleaned, emb_df, on="Date", how="inner")emb_features = [col for col in df.columns if "emb_" in col]
ts_features = [col for col in df.columns if "lag_" in col or "roll_" in col]# IMPORTANT: set 'Date' as the DataFrame index for proper time series splitting
df = df.set_index('Date')
train = df[df.index < "2014-01-01"] # Splitting threshold
test = df[df.index >= "2014-01-01"]
X_train_base = train[ts_features]
X_test_base = test[ts_features]
X_train_full = train[ts_features + emb_features]
X_test_full = test[ts_features + emb_features]
y_train = train["target"]
y_test = test["target"]# Baseline model: no LLM embeddings
model_base = LGBMClassifier(random_state=42)
model_base.fit(X_train_base, y_train)
pred_base = model_base.predict(X_test_base)
acc_base = accuracy_score(y_test, pred_base)
print("Baseline Accuracy:", acc_base)[LightGBM] [Info] Number of positive: 734, number of negative: 625
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000270 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 1530
[LightGBM] [Info] Number of data points in the train set: 1359, number of used features: 6
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.540103 -> initscore=0.160757
[LightGBM] [Info] Start training from score 0.160757
Baseline Accuracy: 0.5# Full model with LLM embeddings
model_full = LGBMClassifier(random_state=42)
model_full.fit(X_train_full, y_train)
pred_full = model_full.predict(X_test_full)
acc_full = accuracy_score(y_test, pred_full)
print("With Embeddings Accuracy:", acc_full)[LightGBM] [Info] Number of positive: 734, number of negative: 625
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000663 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 6630
[LightGBM] [Info] Number of data points in the train set: 1359, number of used features: 26
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.540103 -> initscore=0.160757
[LightGBM] [Info] Start training from score 0.160757
With Embeddings Accuracy: 0.5079365079365079import pandas as pd
from sentence_transformers import SentenceTransformer
from sklearn.decomposition import PCA
from sklearn.metrics import accuracy_score
from lightgbm import LGBMClassifier
# Re-initialize SentenceTransformer with the new model
model = SentenceTransformer("all-mpnet-base-v2")
# Re-generate embeddings
embeddings = model.encode(
df_news["combined"].tolist(),
show_progress_bar=True
)
# Re-perform PCA
pca = PCA(n_components=20)
embeddings_reduced = pca.fit_transform(embeddings)
# Re-create embedding DataFrame
emb_df = pd.DataFrame(
embeddings_reduced,
index=df_news["Date"],
columns=[f"emb_{i}" for i in range(20)]
)
# Reset index and rename Date column for merging
emb_df.reset_index(inplace=True)
emb_df.rename(columns={emb_df.columns[0]: "Date"}, inplace=True)
# Re-merge df_price_cleaned and emb_df
df = pd.merge(df_price_cleaned, emb_df, on="Date", how="inner")
# Re-set 'Date' as the DataFrame index
df = df.set_index('Date')
# Re-split data
train = df[df.index < "2014-01-01"]
test = df[df.index >= "2014-01-01"]
# Re-prepare features for the full model
X_train_full = train[ts_features + emb_features]
X_test_full = test[ts_features + emb_features]
# Re-define y_train and y_test from the new train/test dataframes
y_train = train["target"]
y_test = test["target"]
# Re-train and evaluate the LGBMClassifier
model_full = LGBMClassifier(random_state=42)
model_full.fit(X_train_full, y_train)
pred_full = model_full.predict(X_test_full)
acc_full = accuracy_score(y_test, pred_full)
print("Accuracy with all-mpnet-base-v2 embeddings:", acc_full)
print("Baseline Accuracy (no embeddings):", acc_base)MPNetModel LOAD REPORT from: sentence-transformers/all-mpnet-base-v2
Key | Status | |
------------------------+------------+--+-
embeddings.position_ids | UNEXPECTED | |
Notes:
- UNEXPECTED :can be ignored when loading from different task/architecture; not ok if you expect identical arch.[LightGBM] [Info] Number of positive: 734, number of negative: 625
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000636 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 6630
[LightGBM] [Info] Number of data points in the train set: 1359, number of used features: 26
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.540103 -> initscore=0.160757
[LightGBM] [Info] Start training from score 0.160757
Accuracy with all-mpnet-base-v2 embeddings: 0.5095238095238095
Baseline Accuracy (no embeddings): 0.5import pandas as pd
from sentence_transformers import SentenceTransformer
from sklearn.decomposition import PCA
from sklearn.metrics import accuracy_score
from lightgbm import LGBMClassifier
# Initialize SentenceTransformer with the FinBERT model
model = SentenceTransformer("ProsusAI/finbert")
# Generate embeddings using FinBERT
embeddings = model.encode(
df_news["combined"].tolist(),
show_progress_bar=True
)
# Perform PCA to reduce dimensionality of embeddings
pca = PCA(n_components=20)
embeddings_reduced = pca.fit_transform(embeddings)
# Create a DataFrame for the reduced embeddings
emb_df = pd.DataFrame(
embeddings_reduced,
index=df_news["Date"],
columns=[f"emb_{i}" for i in range(20)]
)
# Reset index and rename Date column for merging
emb_df.reset_index(inplace=True)
emb_df.rename(columns={emb_df.columns[0]: "Date"}, inplace=True)
# Merge price data with FinBERT embeddings
df_finbert = pd.merge(df_price_cleaned, emb_df, on="Date", how="inner")
# Set 'Date' as the DataFrame index for proper time series splitting
df_finbert = df_finbert.set_index('Date')
# Split data into training and testing sets
train_finbert = df_finbert[df_finbert.index < "2014-01-01"]
test_finbert = df_finbert[df_finbert.index >= "2014-01-01"]
# Prepare features for the full model (time series features + FinBERT embeddings)
X_train_full_finbert = train_finbert[ts_features + emb_features]
X_test_full_finbert = test_finbert[ts_features + emb_features]
# Define target variables
y_train_finbert = train_finbert["target"]
y_test_finbert = test_finbert["target"]
# Train and evaluate the LGBMClassifier with FinBERT embeddings
model_full_finbert = LGBMClassifier(random_state=42)
model_full_finbert.fit(X_train_full_finbert, y_train_finbert)
pred_full_finbert = model_full_finbert.predict(X_test_full_finbert)
acc_full_finbert = accuracy_score(y_test_finbert, pred_full_finbert)
print("Accuracy with FinBERT embeddings:", acc_full_finbert)
print("Baseline Accuracy (no embeddings):", acc_base)之後換 Finbert,或是改成 ARIMA 系列預測。
import pandas as pd
import numpy as np
from sentence_transformers import SentenceTransformer
from sklearn.decomposition import PCA
from statsmodels.tsa.arima.model import ARIMA
from sklearn.metrics import mean_squared_error
# 1. Generate 'all-MiniLM-L6-v2' embeddings and process them
print("Generating 'all-MiniLM-L6-v2' embeddings...")
model_llm_c = SentenceTransformer("all-MiniLM-L6-v2")
embeddings_llm_c = model_llm_c.encode(
df_news["combined"].tolist(),
show_progress_bar=True
)
pca_llm_c = PCA(n_components=20)
embeddings_reduced_llm_c = pca_llm_c.fit_transform(embeddings_llm_c)
emb_df_llm_c = pd.DataFrame(
embeddings_reduced_llm_c,
index=df_news["Date"],
columns=[f"LLM-C_{i}" for i in range(20)]
)
emb_df_llm_c.reset_index(inplace=True)
emb_df_llm_c.rename(columns={emb_df_llm_c.columns[0]: "Date"}, inplace=True)
# 2. Prepare data for ARIMA and ARIMAX
# Merge only 'Date' and 'Close' from df_price_cleaned with the new embeddings
df_arima_data = pd.merge(df_price_cleaned[['Date', '^DJI']], emb_df_llm_c, on="Date", how="inner")
df_arima_data = df_arima_data.rename(columns={'^DJI': 'Close'})
df_arima_data = df_arima_data.set_index('Date')
# Split data into training and testing sets (same split as previous tasks)
train_arima = df_arima_data[df_arima_data.index < "2014-01-01"]
test_arima = df_arima_data[df_arima_data.index >= "2014-01-01"]
# Define endogenous and exogenous variables
endog_train = train_arima['Close']
endog_test = test_arima['Close']
exog_train = train_arima[[col for col in train_arima.columns if col.startswith('LLM-C_')]]
exog_test = test_arima[[col for col in test_arima.columns if col.startswith('LLM-C_')]]
print("Data prepared for ARIMA/ARIMAX.")
# 3. Perform ARIMA prediction
print("Fitting ARIMA model...")
# A common starting point for ARIMA order (p, d, q) for financial data
# Here, d=1 for differencing to achieve stationarity, p=5 for autoregressive terms,
# and q=0 for moving average terms (simplified for demonstration).
arima_order = (5, 1, 0)
arima_model = ARIMA(endog_train, order=arima_order)
arima_fit = arima_model.fit()
# Make predictions
# The predict method needs 'start' and 'end' indices relative to the *original* series if using `typ='linear'` or `typ='levels'`
# For out-of-sample prediction, it's often simpler to predict the next `steps` values
# However, statsmodels ARIMA predict handles start/end based on the *original* data index if not explicitly using `steps`
# Let's align it with the test set's length.
start_index = len(endog_train)
end_index = len(df_arima_data) - 1
arima_pred = arima_fit.predict(start=start_index, end=end_index)
# Ensure prediction index matches test set index
arima_pred.index = endog_test.index
rmse_arima = np.sqrt(mean_squared_error(endog_test, arima_pred))
print(f"ARIMA RMSE: {rmse_arima:.4f}")
# 4. Perform ARIMAX prediction
print("Fitting ARIMAX model with LLM-C as exogenous variable...")
arimax_model = ARIMA(endog_train, exog=exog_train, order=arima_order)
arimax_fit = arimax_model.fit()
# Make predictions using the test exogenous variables
arimax_pred = arimax_fit.predict(start=start_index, end=end_index, exog=exog_test)
# Ensure prediction index matches test set index
arimax_pred.index = endog_test.index
rmse_arimax = np.sqrt(mean_squared_error(endog_test, arimax_pred))
print(f"ARIMAX RMSE: {rmse_arimax:.4f}")
# 5. Compare results
print("\n--- Forecast Comparison ---")
print(f"ARIMA Model (RMSE): {rmse_arima:.4f}")
print(f"ARIMAX Model (RMSE): {rmse_arimax:.4f}")
if rmse_arimax < rmse_arima:
print("ARIMAX model with LLM-C embeddings performed better.")
elif rmse_arimax > rmse_arima:
print("ARIMA model performed better (without LLM-C embeddings).")
else:
print("Both models performed similarly.")Generating 'all-MiniLM-L6-v2' embeddings...BertModel LOAD REPORT from: sentence-transformers/all-MiniLM-L6-v2
Key | Status | |
------------------------+------------+--+-
embeddings.position_ids | UNEXPECTED | |
Notes:
- UNEXPECTED :can be ignored when loading from different task/architecture; not ok if you expect identical arch.Data prepared for ARIMA/ARIMAX.
Fitting ARIMA model.../usr/local/lib/python3.12/dist-packages/statsmodels/tsa/base/tsa_model.py:473: ValueWarning: A date index has been provided, but it has no associated frequency information and so will be ignored when e.g. forecasting.
self._init_dates(dates, freq)
/usr/local/lib/python3.12/dist-packages/statsmodels/tsa/base/tsa_model.py:473: ValueWarning: A date index has been provided, but it has no associated frequency information and so will be ignored when e.g. forecasting.
self._init_dates(dates, freq)
/usr/local/lib/python3.12/dist-packages/statsmodels/tsa/base/tsa_model.py:473: ValueWarning: A date index has been provided, but it has no associated frequency information and so will be ignored when e.g. forecasting.
self._init_dates(dates, freq)
/usr/local/lib/python3.12/dist-packages/statsmodels/tsa/base/tsa_model.py:837: ValueWarning: No supported index is available. Prediction results will be given with an integer index beginning at `start`.
return get_prediction_index(
/usr/local/lib/python3.12/dist-packages/statsmodels/tsa/base/tsa_model.py:837: FutureWarning: No supported index is available. In the next version, calling this method in a model without a supported index will result in an exception.
return get_prediction_index(
/usr/local/lib/python3.12/dist-packages/statsmodels/tsa/base/tsa_model.py:473: ValueWarning: A date index has been provided, but it has no associated frequency information and so will be ignored when e.g. forecasting.
self._init_dates(dates, freq)
/usr/local/lib/python3.12/dist-packages/statsmodels/tsa/base/tsa_model.py:473: ValueWarning: A date index has been provided, but it has no associated frequency information and so will be ignored when e.g. forecasting.
self._init_dates(dates, freq)
/usr/local/lib/python3.12/dist-packages/statsmodels/tsa/base/tsa_model.py:473: ValueWarning: A date index has been provided, but it has no associated frequency information and so will be ignored when e.g. forecasting.
self._init_dates(dates, freq)ARIMA RMSE: 939.7920
Fitting ARIMAX model with LLM-C as exogenous variable...
ARIMAX RMSE: 955.3609
--- Forecast Comparison ---
ARIMA Model (RMSE): 939.7920
ARIMAX Model (RMSE): 955.3609
ARIMA model performed better (without LLM-C embeddings)./usr/local/lib/python3.12/dist-packages/statsmodels/tsa/base/tsa_model.py:837: ValueWarning: No supported index is available. Prediction results will be given with an integer index beginning at `start`.
return get_prediction_index(
/usr/local/lib/python3.12/dist-packages/statsmodels/tsa/base/tsa_model.py:837: FutureWarning: No supported index is available. In the next version, calling this method in a model without a supported index will result in an exception.
return get_prediction_index(RMSE 反而升高了XD
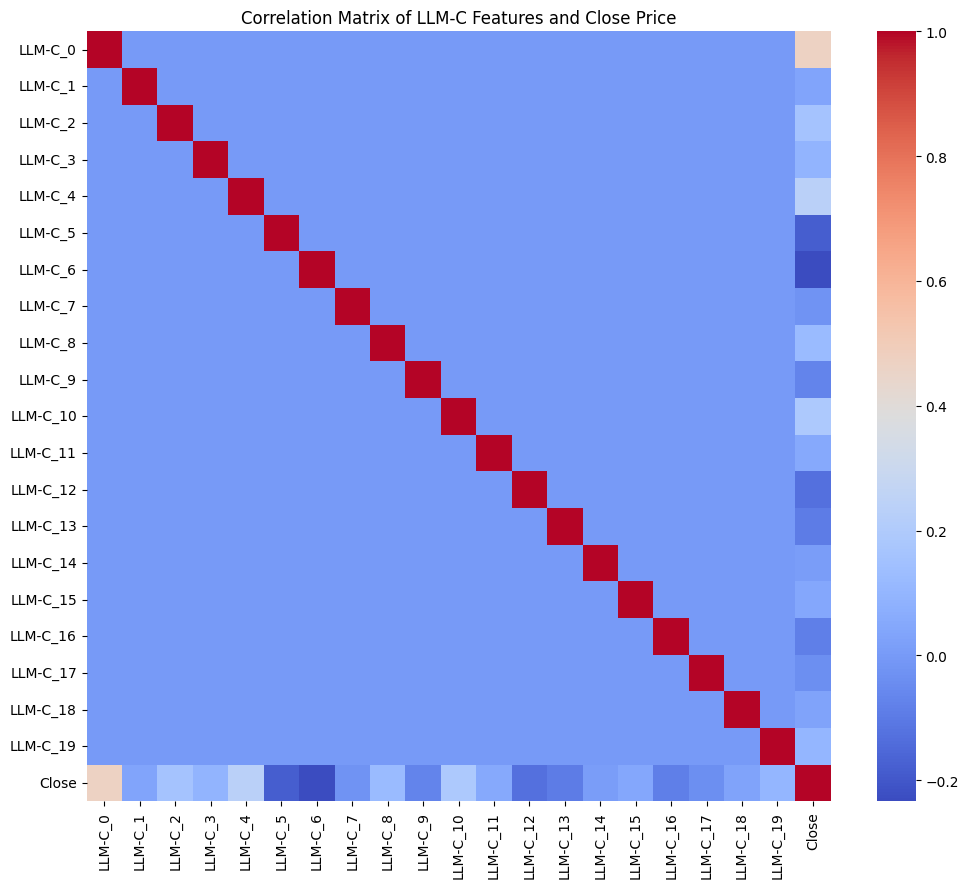
其實也不是不能理解,因為他們與道瓊指數的收盤價關係度很低
import matplotlib.pyplot as plt
import seaborn as sns
# Select the LLM-C features and the 'Close' column
correlation_data = df_arima_data[[col for col in df_arima_data.columns if col.startswith('LLM-C_')] + ['Close']]
# Calculate the correlation matrix
correlation_matrix = correlation_data.corr()
# Display the correlations of LLM-C features with 'Close'
print("Correlation of LLM-C features with ^DJI (Close):")
display(correlation_matrix['Close'].drop('Close').sort_values(ascending=False))
# Optionally, visualize the full correlation matrix as a heatmap
plt.figure(figsize=(12, 10))
sns.heatmap(correlation_matrix, annot=False, cmap='coolwarm', fmt=".2f")
plt.title('Correlation Matrix of LLM-C Features and Close Price')
plt.show()Correlation of LLM-C features with ^DJI (Close):| Close | |
|---|---|
| LLM-C_0 | 0.467255 |
| LLM-C_4 | 0.234261 |
| LLM-C_10 | 0.189574 |
| LLM-C_2 | 0.159234 |
| LLM-C_8 | 0.118701 |
| LLM-C_19 | 0.102356 |
| LLM-C_3 | 0.093199 |
| LLM-C_11 | 0.053757 |
| LLM-C_15 | 0.043168 |
| LLM-C_1 | 0.031072 |
| LLM-C_18 | 0.027534 |
| LLM-C_14 | 0.010395 |
| LLM-C_7 | -0.026103 |
| LLM-C_17 | -0.038395 |
| LLM-C_9 | -0.071486 |
| LLM-C_16 | -0.088449 |
| LLM-C_13 | -0.097439 |
| LLM-C_12 | -0.130530 |
| LLM-C_5 | -0.183246 |
| LLM-C_6 | -0.234155 |
Cite
@article{vaswani2017attention, title={Attention is all you need}, author={Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, {}ukasz and Polosukhin, Illia}, journal={Advances in neural information processing systems}, volume={30}, year={2017} }
無符合的項目