緣起
最近發現 AI 聯盟開了「生成式AI應用系統與工程」,課綱很吸引我,但跟統研的必修衝堂了 QQ ,所以叫 Gemini 根據課綱教我,看看它能教到甚麼程度。
目前發現它教的都是最簡單的部分XD,比較複雜的東西以前端為例,課綱裡列的 Next.js / React / Tailwind 都被自刻 Html/CSS/JavaScript 取代,然後還吹得我好像會了甚麼很厲害的東西一樣 == 。不過它也有教我沒接觸過的 FastAPI,雖然講得超級淺,但能 Build 出自己的 API 服務滿有成就感的,除此之外還可以觀察有使用 LLM 的系統服務是怎麼串的,所以有了這篇文章。
- 建立新的專案資料夾
- 建立新的乾淨虛擬環境
IDE: Vscode
Python version: 3.12.5 (venv 虛擬環境)
另外,也記錄本次 requirement.txt,實際上我是跟著 Gemini 的指示做 pip install,所以我覺得沒必要先安裝好這些,但可以參考。
annotated-doc==0.0.4
annotated-types==0.7.0
anyio==4.12.1
certifi==2026.1.4
charset-normalizer==3.4.4
click==8.3.1
colorama==0.4.6
distro==1.9.0
fastapi==0.128.0
filelock==3.20.3
fsspec==2026.1.0
groq==1.0.0
h11==0.16.0
httpcore==1.0.9
httpx==0.28.1
huggingface-hub==0.36.0
idna==3.11
Jinja2==3.1.6
jiter==0.12.0
joblib==1.5.3
MarkupSafe==3.0.3
mpmath==1.3.0
networkx==3.6.1
numpy==2.4.1
openai==2.15.0
packaging==25.0
pydantic==2.12.5
pydantic_core==2.41.5
PyYAML==6.0.3
regex==2026.1.15
requests==2.32.5
safetensors==0.7.0
scikit-learn==1.8.0
scipy==1.17.0
sentence-transformers==5.2.0
setuptools==80.9.0
sniffio==1.3.1
starlette==0.50.0
sympy==1.14.0
threadpoolctl==3.6.0
tokenizers==0.22.2
torch==2.9.1
tqdm==4.67.1
transformers==4.57.6
typing-inspection==0.4.2
typing_extensions==4.15.0
urllib3==2.6.3
uvicorn==0.40.0申請 Groq 免費 API Key 並測試
因為 OpenAI API 要 $$,所以我叫它改用免費的 Groq :P。
申請步驟
完整申請步驟如下:1
上去官網,點選右上角的 Start Building
建立帳號登入
點選右上方的 API Keys,進入後選擇大大的「+ Create API Key」
給 API 命名後 Submit,copy API。
測試
接著在乾淨的 venv 環境下安裝套件
pip install openai然後在專案資料夾下建立 main.py 或其他 py 檔,輸入以下程式(記得修改 API KEY):
from openai import OpenAI
# 1. 設定連線資訊
# base_url 是關鍵,這行告訴程式:「不要連去 OpenAI,改連去 Groq」
client = OpenAI(
api_key="剛剛申請的API KEY",
base_url="https://api.groq.com/openai/v1"
)
print("--- 免費 AI 聊天機器人 (Groq Llama3) 啟動 ---")
print("--- 輸入 'quit' 可以離開程式 ---")
while True:
# 2. 讓使用者輸入
user_input = input("\n你:")
if user_input.lower() == "quit":
print("再見!")
break
# 3. 呼叫 AI (這裡使用開源模型 Llama3-8b)
try:
completion = client.chat.completions.create(
model="llama-3.3-70b-versatile", # 指定模型名稱
messages=[
{"role": "system", "content": "你是一個繁體中文的 AI 助教,回答簡潔有力。"},
{"role": "user", "content": user_input}
]
)
# 4. 取得回答
ai_response = completion.choices[0].message.content
print(f"AI:{ai_response}")
except Exception as e:
print(f"發生錯誤:{e}")然後跑跑看腳本,如果能在 Terminal 跟模型對話就成功了,如果失敗,則有可能是 API Key 錯誤或是模型不支援要更換。這裡我們用的模型是llama-3.3-70b-versatile。
如果點進去 Groq 官網,會發現它們用的是 Groq()而非 OpenAI()建立 Client,這主要是因為:
時序上 OpenAI 較早提供 API 服務,在使用者增加後其他公司才後續跟進
OpenAI()也支援連接其他 LLM 的 API 服務,泛用性較高觀察網路上的常見的 LLM 服務課程,開發程式碼也以
OpenAI()為主
所以就用OpenAI()囉!
base_url 是啥
base_url 就是伺服器的地址。想像你在寄信(發送請求):
信的內容 (Payload): 你的問題(例如:“你好”)。
信的格式 (Schema): OpenAI 規定的格式(JSON 格式)。
收件地址 (base_url): 這就是關鍵所在。
預設情況 (不寫 base_url):當你只寫 client = OpenAI(api_key=“…”) 時,程式預設的 base_url 是 https://api.openai.com/v1 (直接寄去 OpenAI 總部)。
我們的情況 (修改 base_url):當你加上 base_url=“https://api.groq.com/openai/v1” 時,發生了這件事:你的程式依然使用 OpenAI 的格式打包信件,但是信件被攔截,轉送到了 Groq 的伺服器。Groq 的伺服器看懂了這個格式 (因為它相容),於是處理後回傳結果。
同理,假設我們今天要改成在本地跑 Ollama 模型,可以把 base_url改成自己的電腦地址,ex base_url="http://localhost:11111/v1"。
建立後端 API 服務
首先,在乾淨的 venv 環境下安裝套件
pip install fastapi uvicorn說明:
FastAPI: 用來快速建立網頁伺服器的框架。
Uvicorn: 用來啟動這個伺服器的工具。
在專案資料夾下建立 server.py,內容打一下(一樣要修改API KEY):
from fastapi import FastAPI
from pydantic import BaseModel
from openai import OpenAI
# 1. 初始化 FastAPI APP
app = FastAPI()
# 2. 設定 Groq 連線 (跟上一步一樣)
client = OpenAI(
api_key="你申請的API Key",
base_url="https://api.groq.com/openai/v1"
)
# 3. 定義資料格式:告訴程式,別人傳進來的資料應該長什麼樣子
# 這裡規定:一定要有一個欄位叫做 "message" 且是文字 (str)
class UserInput(BaseModel):
message: str
# 4. 建立一個 "路徑" (API Endpoint)
# 當有人對網址 /chat 發送 POST 請求時,會執行這個函式
@app.post("/chat")
def chat_with_ai(data: UserInput):
user_message = data.message
print(f"收到訊息:{user_message}") # 讓你在後台看得到
try:
# 呼叫 Groq
completion = client.chat.completions.create(
model="llama-3.3-70b-versatile",
messages=[
{"role": "system", "content": "你是一個繁體中文 AI 助教。"},
{"role": "user", "content": user_message}
]
)
ai_reply = completion.choices[0].message.content
# 回傳結果給前端
return {"reply": ai_reply}
except Exception as e:
return {"error": str(e)}
# 5. 測試首頁 (確認伺服器活著)
@app.get("/")
def read_root():
return {"status": "Server is running!", "course": "Generative AI Engineering"}這裡使用的測試模型一樣是llama-3.3-70b-versatile。然後用
uvicorn server:app --reload啟動伺服器,成功時 Terminal 會顯示的訊息
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
...
...
...
INFO: ... - "GET / HTTP/1.1" 200 OK
INFO: ... - "GET /docs HTTP/1.1" 200 OK
INFO: ... - "GET /openapi.json HTTP/1.1" 200 OK且到 http://127.0.0.1:8000時,畫面會像這樣
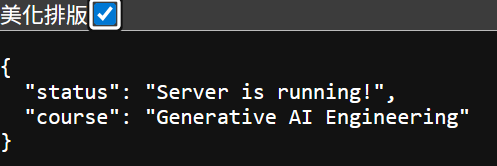
這個成功畫面顯示的就是第五步的 code,但其實第五步不是必須,只是可以直接確認伺服器可正常運作,完全不寫的話 INFO 會跑出 404 Not Found 的訊息,打開網站也會跑出 404 的訊息,但我們可以用一個簡單的方式確認:
首先打開 API 文件 http://127.0.0.1:8000/docs。
依序點擊
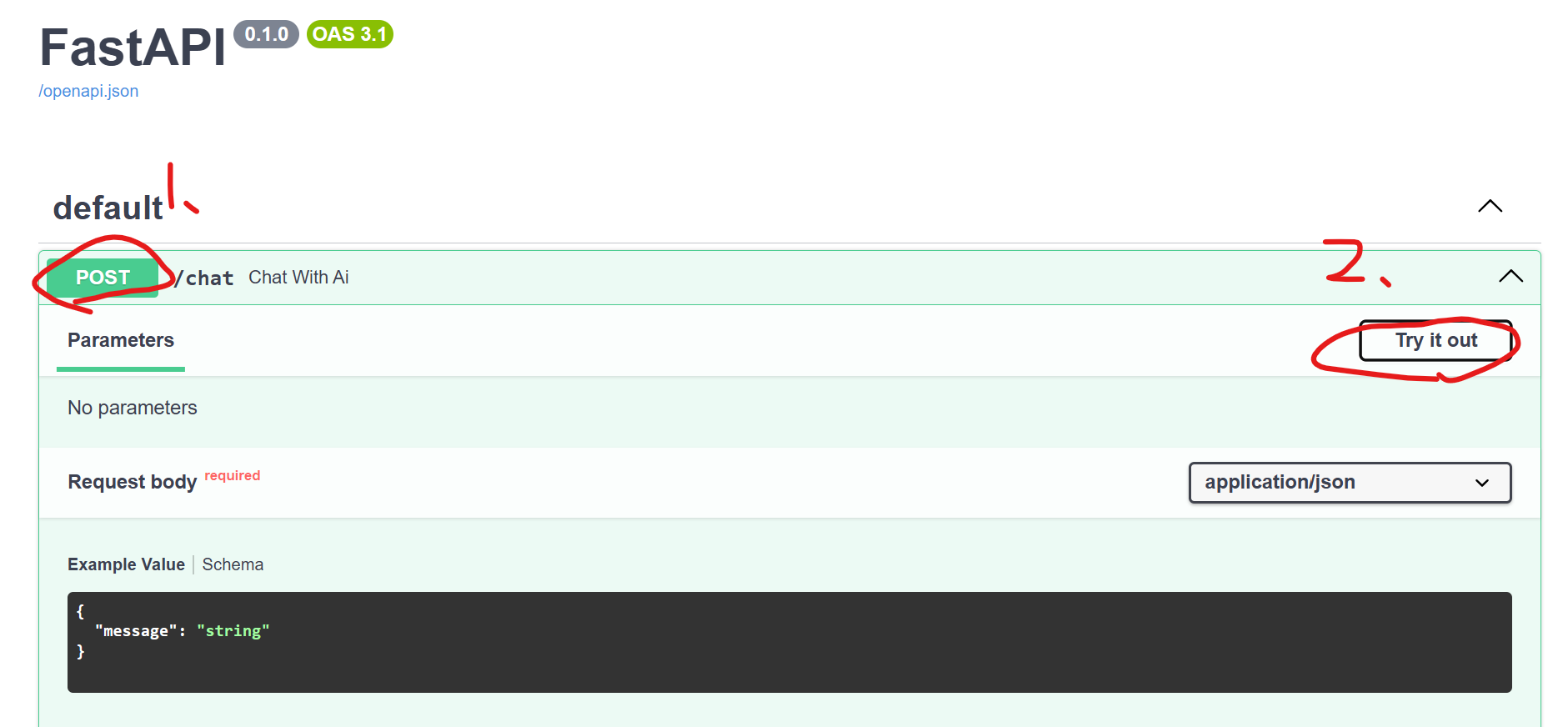 3. 修改 “string”部分(模仿使用者輸入問題)
3. 修改 “string”部分(模仿使用者輸入問題)
{
"message": "string"
}按下 Execute 按鈕
查看下方 Response 部分, Code 200 代表正常運作,且可以看到 Response Body 有模型回應跟 Response Header 紀錄回應時間等資訊。
實務上 API 文件在開發跟檢查問題時都很需要,學起來不是壞事:)
如果連 API KEY 都不能隱藏的話,要怎麼上線!首先再來安裝一個套件
pip install dotenv接著在同專案資料夾下建立名為 .env 的檔案,建立變數:
API_KEY="你申請的API KEY"可以用以下腳本試跑看看 Terminal 可不可以成功顯示 API_KEY裡的參數。
import os
from dotenv import load_dotenv
load_dotenv() # 讀取 .env
API_KEY = os.getenv("API_KEY") # 取得 API_KEY 這個參書內容
print(API_KEY)成功的話再把這段程式貼入 server.py 裡。
網頁服務的建立
上一個 part 的程式只能在後端運作,使用者用不了,所以需要前端讓使用者輸入東西,傳給後端處理。這裡使用比較常見的網頁服務來實作,而且是用最簡單的 HTML 包 CSS 跟 JS 的形式。
不過首先要先讓網頁跟伺服器可以溝通,就要先解決瀏覽器的安全機制 (CORS)。
所謂的 CORS 就是,網頁檔案 (HTML) 和伺服器 (FastAPI) 雖然都在同一台電腦,但在瀏覽器眼中它們是「不同的來源」。如果沒有特別允許,瀏覽器會禁止網頁去讀取伺服器的資料。所以要修改 server.py變成:
# 建立 web
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware # [NEW] 引入 CORS 套件
from pydantic import BaseModel
from openai import OpenAI
app = FastAPI()
# [NEW] 設定 CORS,允許所有來源 (為了開發方便,我們先全開)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 允許任何網址呼叫這個 API
allow_credentials=True,
allow_methods=["*"], # 允許任何方法 (GET, POST...)
allow_headers=["*"],
)
client = OpenAI(
api_key="APIKEY",
base_url="https://api.groq.com/openai/v1"
)
# 後面都一樣| 參數名稱 | 設定值 | 功能說明 |
|---|---|---|
| allow_origins | [“*”] | 允許的來源網域。[“*”] 代表「允許所有網站」存取你的 API。在開發階段很方便,但在正式上線(Production)時,建議指定具體的網址(例如 [“https://www.your-app.com”])以策安全。 |
| allow_credentials | True | 是否允許攜帶憑證。當設為 True 時,跨來源請求可以包含 Cookies、HTTP 認證(Authentication)或 TLS 用戶端憑證。注意:如果此項為 True,allow_origins 最好不要設為 [“*”],有些瀏覽器會因為安全限制而報錯。 |
| allow_methods | [“*”] | 允許的 HTTP 方法。[“*”] 代表允許所有方法,包括 GET、POST、PUT、DELETE 等。你目前的程式碼中使用了 POST 方法來處理 /chat 和 /upload。 |
| allow_headers | [“*”] | 允許的 HTTP 標頭。[“*”] 代表允許請求攜帶任何自定義標頭(Headers),例如 Content-Type、Authorization 等。 |
AI 目前給的設定都是安全最低的選擇,有部署需要時需要調整(尤其是allow_origins)。
然後建立網頁index.html
<!DOCTYPE html>
<html lang="zh-TW">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>我的 AI 聊天室</title>
<style>
/* 簡單的 CSS 樣式,讓畫面好看一點 */
body { font-family: sans-serif; max-width: 600px; margin: 20px auto; padding: 0 20px; }
.chat-box { border: 1px solid #ccc; height: 400px; overflow-y: scroll; padding: 10px; margin-bottom: 10px; border-radius: 5px; background: #f9f9f9; }
.message { margin: 10px 0; padding: 8px 12px; border-radius: 10px; width: fit-content; max-width: 80%; }
.user { background-color: #007bff; color: white; margin-left: auto; text-align: right; } /* 使用者訊息靠右 */
.ai { background-color: #e9ecef; color: black; margin-right: auto; } /* AI 訊息靠左 */
.input-area { display: flex; gap: 10px; }
input { flex: 1; padding: 10px; border-radius: 5px; border: 1px solid #ddd; }
button { padding: 10px 20px; background-color: #28a745; color: white; border: none; border-radius: 5px; cursor: pointer; }
button:hover { background-color: #218838; }
button:disabled { background-color: #ccc; }
</style>
</head>
<body>
<h2>🤖 我的生成式 AI 助手</h2>
<div class="chat-box" id="chat-box">
<div class="message ai">你好!我是你的 AI 助教,有什麼我可以幫你的嗎?</div>
</div>
<div class="input-area">
<input type="text" id="user-input" placeholder="輸入你的問題..." onkeypress="handleEnter(event)">
<button onclick="sendMessage()" id="send-btn">發送</button>
</div>
<script>
// 3. JavaScript 邏輯區:負責跟後端講話
async function sendMessage() {
const inputField = document.getElementById("user-input");
const sendBtn = document.getElementById("send-btn");
const chatBox = document.getElementById("chat-box");
const message = inputField.value.trim();
if (!message) return; // 如果沒輸入字就不理會
// 顯示使用者的訊息
appendMessage(message, "user");
inputField.value = ""; // 清空輸入框
sendBtn.disabled = true; // 發送中禁止按按鈕
sendBtn.innerText = "思考中...";
try {
// --- 關鍵步驟:呼叫你的 FastAPI 後端 ---
const response = await fetch("http://127.0.0.1:8000/chat", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ message: message })
});
const data = await response.json();
// 顯示 AI 的回答
if (data.reply) {
appendMessage(data.reply, "ai");
} else {
appendMessage("錯誤:" + JSON.stringify(data), "ai");
}
} catch (error) {
appendMessage("連線失敗,請確認後端伺服器有開啟。", "ai");
console.error(error);
}
// 恢復按鈕狀態
sendBtn.disabled = false;
sendBtn.innerText = "發送";
}
// 輔助功能:把訊息加到畫面上
function appendMessage(text, sender) {
const chatBox = document.getElementById("chat-box");
const div = document.createElement("div");
div.classList.add("message", sender);
div.innerText = text;
chatBox.appendChild(div);
chatBox.scrollTop = chatBox.scrollHeight; // 自動捲動到底部
}
// 輔助功能:按 Enter 鍵也能發送
function handleEnter(event) {
if (event.key === "Enter") sendMessage();
}
</script>
</body>
</html>然後在伺服器已啟動的前提下用瀏覽器開啟網頁,成功時可以正常跟它對話,正常流程為:
Frontend (HTML/JS): 瀏覽器抓取你輸入的文字。
API Call: 瀏覽器發送請求給 http://127.0.0.1:8000/chat。
Backend (FastAPI): 你的 Python 程式收到請求,轉頭去問 Groq。
LLM: Groq 運算完,把結果傳回 Python。
Render: Python 把結果傳回瀏覽器,JavaScript 把文字貼在畫面上。
但它還不具備逐字載入與上下文記憶功能。
細節微調
讓網頁逐字載入回應
先修改 serve.py,首先在套件部分加入
from fastapi.responses import StreamingResponse # [NEW] 引入串流回應再去修改回傳函數
# [NEW] 這裡我們不直接回傳,而是寫一個 "產生器 (Generator)"
# 它的功能是:一邊收 Groq 的資料,一邊吐給前端
def get_ai_response_stream(user_message: str):
try:
completion = client.chat.completions.create(
model="llama-3.3-70b-versatile",
messages=[
{"role": "system", "content": "你是一個繁體中文 AI 助教。"},
{"role": "user", "content": user_message}
],
stream=True # [關鍵] 告訴 Groq 我們要用串流模式
)
for chunk in completion:
# 檢查這個碎片有沒有內容
content = chunk.choices[0].delta.content
if content:
yield content # "yield" 意思是產出一個碎片就馬上送出去
except Exception as e:
yield f"Error: {str(e)}"
@app.post("/chat")
def chat_with_ai(data: UserInput):
print(f"收到訊息 (串流模式):{data.message}")
# 回傳一個 "串流回應",而不是一般的 JSON
return StreamingResponse(
get_ai_response_stream(data.message),
media_type="text/plain"
)再來改前端部分,主要是要修改 Javascripts 部分,讓回應可以產生逐字載入的動畫效果:
<script>
async function sendMessage() {
const inputField = document.getElementById("user-input");
const sendBtn = document.getElementById("send-btn");
const chatBox = document.getElementById("chat-box");
const message = inputField.value.trim();
if (!message) return;
// 1. 顯示使用者訊息
appendMessage(message, "user");
inputField.value = "";
sendBtn.disabled = true;
sendBtn.innerText = "思考中...";
// 2. 準備接收 AI 的回答 (先建立一個空的對話框)
const aiMessageDiv = appendMessage("", "ai");
try {
const response = await fetch("http://127.0.0.1:8000/chat", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ message: message })
});
// [NEW] 處理串流資料的關鍵邏輯
const reader = response.body.getReader();
const decoder = new TextDecoder("utf-8");
while (true) {
const { done, value } = await reader.read();
if (done) break; // 如果讀完了就跳出迴圈
// 把讀到的二進位資料轉成文字
const chunk = decoder.decode(value, { stream: true });
// 把文字 "追加" 到目前的對話框裡,而不是覆蓋
aiMessageDiv.innerText += chunk;
// 自動捲動到底部
chatBox.scrollTop = chatBox.scrollHeight;
}
} catch (error) {
aiMessageDiv.innerText = "連線發生錯誤。";
console.error(error);
}
sendBtn.disabled = false;
sendBtn.innerText = "發送";
}
// 輔助功能:建立訊息框並回傳該元素 (讓我們可以持續更新它)
function appendMessage(text, sender) {
const chatBox = document.getElementById("chat-box");
const div = document.createElement("div");
div.classList.add("message", sender);
div.innerText = text;
chatBox.appendChild(div);
chatBox.scrollTop = chatBox.scrollHeight;
return div; // 回傳這個 div,讓外面的程式可以繼續塞字進去
}
function handleEnter(event) {
if (event.key === "Enter") sendMessage();
}
</script>不意外的超級長,根本可以拆成獨立檔案了
測試有沒有成功跟前面一樣,只要確定伺服器有再跑,網頁重整後輸入 Prompt 觀察即可。
上下文記憶
LLM 本質上是 「無狀態 (Stateless)」 的,意思就是說:每一次呼叫 API,對它來說都是全新的開始,它完全不記得上一秒發生了什麼。所以我們需要把之前的對話紀錄,全部打包再一次寄給它,讓它看起來好像具備了記憶能力。
一樣先修改 serve.py,首先在套件部分加入
from typing import List, Dict # [NEW] 引入型別定義再去修改資料模型與回傳函數:
# [NEW] 修改資料模型:不再只是單一字串,而是接受一個列表 (List)
# 格式會像這樣:[{"role": "user", "content": "hi"}, {"role": "assistant", "content": "hello"}]
class UserInput(BaseModel):
messages: List[Dict[str, str]]
def get_ai_response_stream(messages_history: List[Dict[str, str]]):
try:
# [NEW] 這裡不再是寫死的 system prompt + user message
# 而是直接把前端傳來的 "整包歷史紀錄" 丟給 Groq
# 我們可以在最前面偷偷加一個 System Prompt 設定 AI 人設
system_prompt = [{"role": "system", "content": "你是一個繁體中文 AI 助教,記憶力很好。"}]
full_context = system_prompt + messages_history
completion = client.chat.completions.create(
model="llama-3.3-70b-versatile",
messages=full_context, # 這裡放入完整的對話歷史
stream=True
)
for chunk in completion:
content = chunk.choices[0].delta.content
if content:
yield content
except Exception as e:
yield f"Error: {str(e)}"
@app.post("/chat")
def chat_with_ai(data: UserInput):
# print(f"收到歷史對話,長度:{len(data.messages)}") # 除錯用
return StreamingResponse(
get_ai_response_stream(data.messages),
media_type="text/plain"
)可以觀察到除了程式越來越長以外,送給模型的不再只有 System Prompt,也有歷史對話訊息。
再來需要修改前端,讓它可以記錄之前的對話訊息,送入後端,一樣改index.html的 JavaScripts 部分:
<script>
// [NEW] 用來暫存對話紀錄的變數
let conversationHistory = [];
async function sendMessage() {
const inputField = document.getElementById("user-input");
const sendBtn = document.getElementById("send-btn");
const chatBox = document.getElementById("chat-box");
const message = inputField.value.trim();
if (!message) return;
// 1. 顯示並紀錄使用者的訊息
appendMessage(message, "user");
// [NEW] 把使用者的話加入歷史紀錄
conversationHistory.push({ "role": "user", "content": message });
inputField.value = "";
sendBtn.disabled = true;
sendBtn.innerText = "思考中...";
const aiMessageDiv = appendMessage("", "ai");
let fullAiResponse = ""; // 用來收集 AI 的完整回答
try {
// [NEW] 傳送 "整包歷史紀錄" 給後端
const response = await fetch("http://127.0.0.1:8000/chat", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ messages: conversationHistory })
});
const reader = response.body.getReader();
const decoder = new TextDecoder("utf-8");
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value, { stream: true });
aiMessageDiv.innerText += chunk;
fullAiResponse += chunk; // 收集碎片
chatBox.scrollTop = chatBox.scrollHeight;
}
// [NEW] AI 講完後,把它的話也加入歷史紀錄
conversationHistory.push({ "role": "assistant", "content": fullAiResponse });
} catch (error) {
aiMessageDiv.innerText = "連線發生錯誤。";
console.error(error);
}
sendBtn.disabled = false;
sendBtn.innerText = "發送";
}
function appendMessage(text, sender) {
const chatBox = document.getElementById("chat-box");
const div = document.createElement("div");
div.classList.add("message", sender);
div.innerText = text;
chatBox.appendChild(div);
chatBox.scrollTop = chatBox.scrollHeight;
return div;
}
function handleEnter(event) {
if (event.key === "Enter") sendMessage();
}
</script>最後重整網頁,輸入需要上下文記憶的問題,看它能不能正確回應、順順的跟你聊下去。
RAG 系統
重點終於來啦,RAG 的概念因為我已經學過,就不贅述,直接進入程式部分。
先建立簡單的 RAG
安裝套件
pip install sentence-transformers scikit-learn然後建立一個簡單的資料來源faq_data.py
# 這只是一個簡單的模擬資料庫 (Dictionary)
# 實務上這裡會是 PDF 檔案或資料庫
knowledge_base = [
{
"id": 1,
"content": "關於請假:本公司員工每年享有 14 天特休,請假需提前 3 天在 HR 系統申請。"
},
{
"id": 2,
"content": "關於加班費:平日加班費為 1.33 倍,假日加班費為 1.66 倍,需經理核准。"
},
{
"id": 3,
"content": "關於午餐:公司每日中午 12:00 提供免費便當,素食者需在 10:00 前登記。"
},
{
"id": 4,
"content": "關於在家工作 (WFH):每週三為固定 WFH 日,其餘時間需進辦公室。"
}
]建立一個新的 rag_service.py
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
from faq_data import knowledge_base
import numpy as np
print("正在載入 Embedding 模型 (第一次會比較久)...")
# 下載一個輕量級的中文模型 (這會存在你的電腦裡)
model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
# 1. 先把知識庫裡的每一條資料,都轉換成「向量 (Vector)」並存起來
# 這樣待會搜尋速度才會快
print("正在建立索引...")
knowledge_texts = [item["content"] for item in knowledge_base]
knowledge_embeddings = model.encode(knowledge_texts)
print("索引建立完成!")
def search_knowledge_base(query, top_k=1):
"""
輸入使用者的問題 (query),回傳最相似的 k 筆資料
"""
# 2. 把使用者的問題也變成向量
query_embedding = model.encode([query])
# 3. 計算相似度 (Cosine Similarity)
# 比較「問題向量」跟所有「知識庫向量」的距離
similarities = cosine_similarity(query_embedding, knowledge_embeddings)
# 4. 找出分數最高的 top_k 個結果
# argsort 會回傳排序後的索引,我們取最後 top_k 個 (分數最高的)
top_indices = similarities[0].argsort()[-top_k:][::-1]
results = []
for idx in top_indices:
score = similarities[0][idx]
if score > 0.3: # 設定一個門檻,相關度太低就不採用 (避免誤導)
results.append(knowledge_base[idx]["content"])
return results
# 測試用 (當你直接執行這個檔案時會跑這段)
if __name__ == "__main__":
test_query = "請問加班有錢拿嗎?"
print(f"\n測試搜尋:{test_query}")
print(search_knowledge_base(test_query))跑這支腳本,成功的話會出現資料庫裡,加班費的計算方式。
整合進後端
修改 server.py 的套件部分跟get_ai_response_stream():
from rag_service import search_knowledge_base # [NEW] 引入搜尋功能這裡抓的是同資料夾下,rag_service.py 的 search_knowledge_base() 函數,如果是放在專案資料夾下的另一個資料夾(假設叫 another_folder )則需這樣讀取
from another_folder.rag_service import search_knowledge_base # [NEW] 引入搜尋功能# ... (中間設定不變)
def get_ai_response_stream(messages_history: List[Dict[str, str]]):
try:
# 1. 抓出使用者最新的一句話
latest_user_message = messages_history[-1]["content"]
# 2. [RAG 核心] 先去知識庫搜尋有沒有相關資料
print(f"正在搜尋知識庫:{latest_user_message}")
retrieved_info = search_knowledge_base(latest_user_message)
system_instruction = "你是一個繁體中文 AI 助教。"
# 3. 如果有搜到資料,就把它塞進 System Prompt 裡
if retrieved_info:
print(f"搜到資料:{retrieved_info}")
context_str = "\n".join(retrieved_info)
# 這裡就是 RAG 的精隨:把資料貼給 AI 看
system_instruction += f"\n\n【參考資料】:\n{context_str}\n\n請根據上述【參考資料】回答使用者的問題。如果資料裡沒有答案,請說不知道,不要瞎掰。"
else:
print("沒搜到相關資料")
# 重新組裝 messages
# 我們把原本的 messages_history 保留,但把第一句 system prompt 換掉
current_messages = [{"role": "system", "content": system_instruction}]
# 把使用者之前的對話紀錄接在後面 (除了第一句 system prompt)
# 注意:這裡邏輯要小心,我們假設 messages_history 都是 user/assistant 的對話
for msg in messages_history:
if msg["role"] != "system":
current_messages.append(msg)
completion = client.chat.completions.create(
model="llama-3.3-70b-versatile",
messages=current_messages,
stream=True
)
for chunk in completion:
content = chunk.choices[0].delta.content
if content:
yield content
except Exception as e:
yield f"Error: {str(e)}"
# ... (後面不變)前端不用改,直接進入網頁測試
測試 1 (基本題): 問它:「你好。」(它應該正常回答)
測試 2 (RAG 題): 問它:「請問公司中午有便當吃嗎?」
測試 3 (RAG 題): 問它:「我想申請 WFH,星期幾可以?」
若有成功按照資料庫回答問題表示成功。
啟動伺服器時,首次執行會進行 Embedding 步驟,耗時較長,需耐心等候,如果要加快速度,實務上會用 Chrome DB 儲存切好 chunk的資料。
暫時性結論
其實它後面還介紹了上傳 PDF 、包成 Docker 之類的服務,但我累惹先停在這,不過還是沒有介紹到課綱裡的前端框架跟服務,感覺它完全自己走自己的==。
後面的東西有空再來繼續,希望可以實現包 Docker 成功初體驗~~
有用的參考資料
官方文件絕對是最好的一手資料來源:
其次是其他工程師寫過的文章
腳註
AI 多半會直接給,不過我還是列一下從搜尋結果進入官網的步驟。↩︎