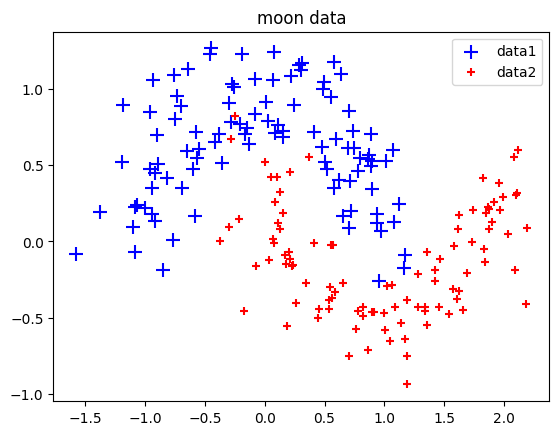
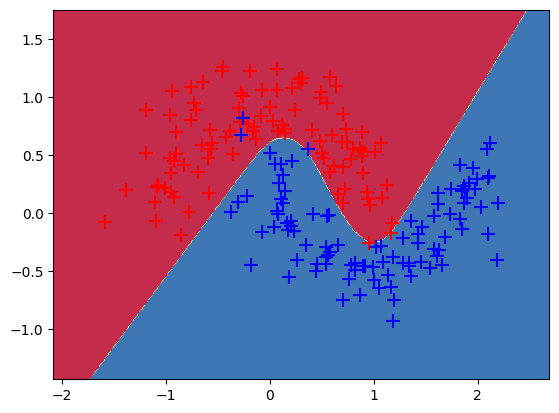
因為只是模擬資料,我們略過區分訓練集與測試集的步驟,直接來建立模型。本次使用一個簡單的兩層nn模型LogicNet,這個模型可視作羅吉斯迴歸的延伸,只是多個隱藏層(hidden layer)的設定。一個 nn 模型中還會需要搭配損失函數,這裡配的是交叉熵損失函數(Cross-Entrop)用來做分類。
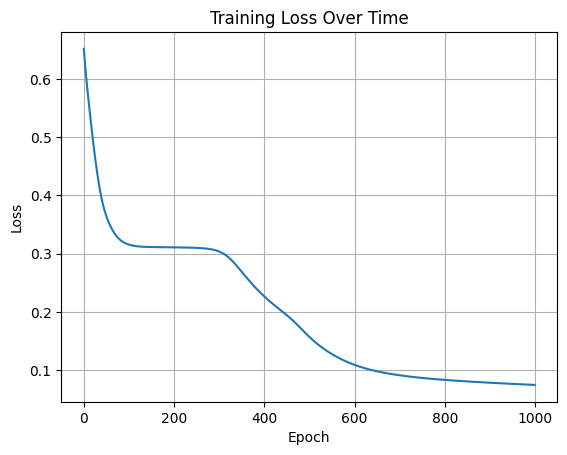
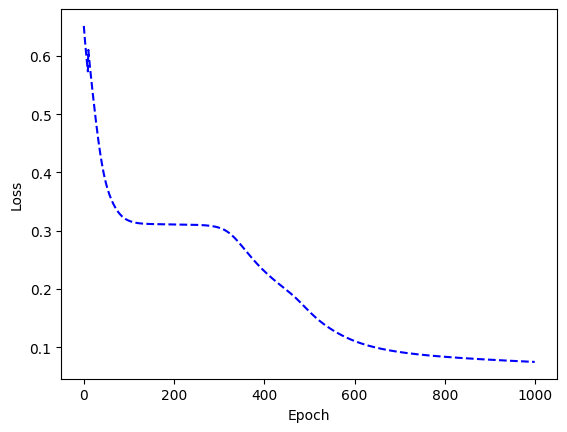
這裡除了 activation function 外,還定義了 criterion,即 loss function。loss function是決定模型學習品質的關鍵,用來計算輸出值與目標值間的誤差。一般在連續的實數資料上會用 MSE ,不過在實務上會根據不同的結構、任務決定不同的 loss function ,這裡使用的是交叉熵損失函數(Cross Entropy Loss),適用於分類問題。
model = LogicNet(inputdim=2, hiddendim=3, outputdim =2)optimizer = torch.optim.Adam(model.parameters(), lr=0.01 )# 印出模型資訊print("model structure and loss function/criterion: \n")print(model)print("optimizer is : \n")print(optimizer)
model structure and loss function/criterion:
LogicNet(
(Linear1): Linear(in_features=2, out_features=3, bias=True)
(Linear2): Linear(in_features=3, out_features=2, bias=True)
(criterion): CrossEntropyLoss()
)
optimizer is :
Adam (
Parameter Group 0
amsgrad: False
betas: (0.9, 0.999)
capturable: False
decoupled_weight_decay: False
differentiable: False
eps: 1e-08
foreach: None
fused: None
lr: 0.01
maximize: False
weight_decay: 0
)
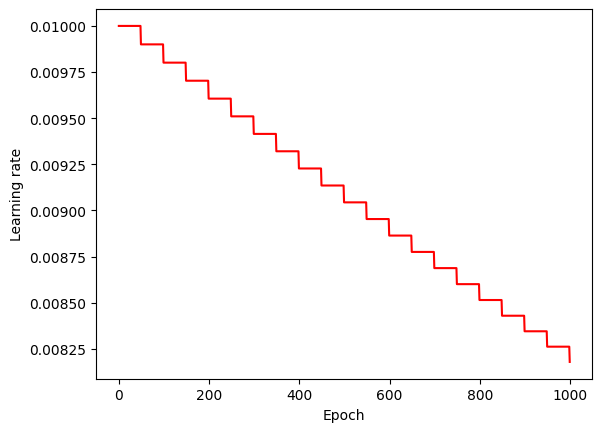
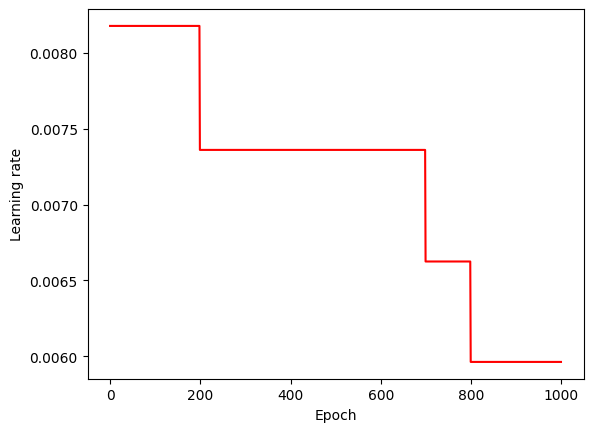
學習率(learning rate)
lr = 學習率(learning rate)learning rate,代表控制模型中梯度下降的速度,它決定了每次迭代的步長,使得optimizer向損失函數的最小值前進。數值越小,模型越能訓練準確,但相對應訓練較耗時。
If $_i$ is the predicted value of the $i$-th sample and \(y_i\) is the corresponding true value, then the fraction of correct predictions over \(n_{samples}\) samples is defined as: