graph TD
A["下載交通部資料"] --> B["清洗資料"]
B --> C["補齊缺失資料"]
C --> D["區分 training set、valid set、test set"]
D --> E["LSTM 模型建模"]
E --> F["依路段產出資料"]
F --> G["計算到達所需時間"]
G --> H["Web 呈現"]
前言
這個 Side Project 的發想完全來自我個人生活中的需求。
以前在大學時認識了一些台中人,或是畢業後留在台中工作的人,加上在在大學生活期間我愛上在台中的生活,畢業後即使在台北工作,有空時我還是會跟朋友約一約,前一天回到新竹,隔天搭乘新竹客運跟著新竹的朋友一起跑到朝馬去找老朋友吃飯、聊天、唱歌。不過這種難得的假日聚會,住在台中的朋友總是會事先負責訂位,確保我們都有店可去。而我們呢,則是負責不要遲到XD
通常為了避免遲到,我跟朋友通常會搭早一點的客運出發。長久搭下來,發現主要影響客運的因素為會不會在國道路上塞車,經驗上來說,到台中時都會塞一小段,而在市區移動的路程時間基本上都是固定的,不會塞車。自從知道交通部有國道車流的開放資料後,我就想嘗試看看用國道的資料建模,看看能不能用神奇的 “占卜” ,讓我們成為時間精算師,再也不要搭這麼早的客運了!XD
需求架構
我的需求架構為:
- 建一個簡單的網站,當使用者輸入客運出發時間時,會顯示客運預計到達朝馬(台灣大道)的時間。
不過因為我手上只有國道的車流資料,實際客運會在市區停留靠站,所幸花費時間基本上都是固定的,所以我只有預測客運在國道上的時間,市區停留靠站固定設定為45分鐘。
此外,因為設備跟預算上的限制,我的預測資料是事先準備好(預測好),再交由網站呈現。
最後做出來的東西,先用 Streamlit 套件來Demo:
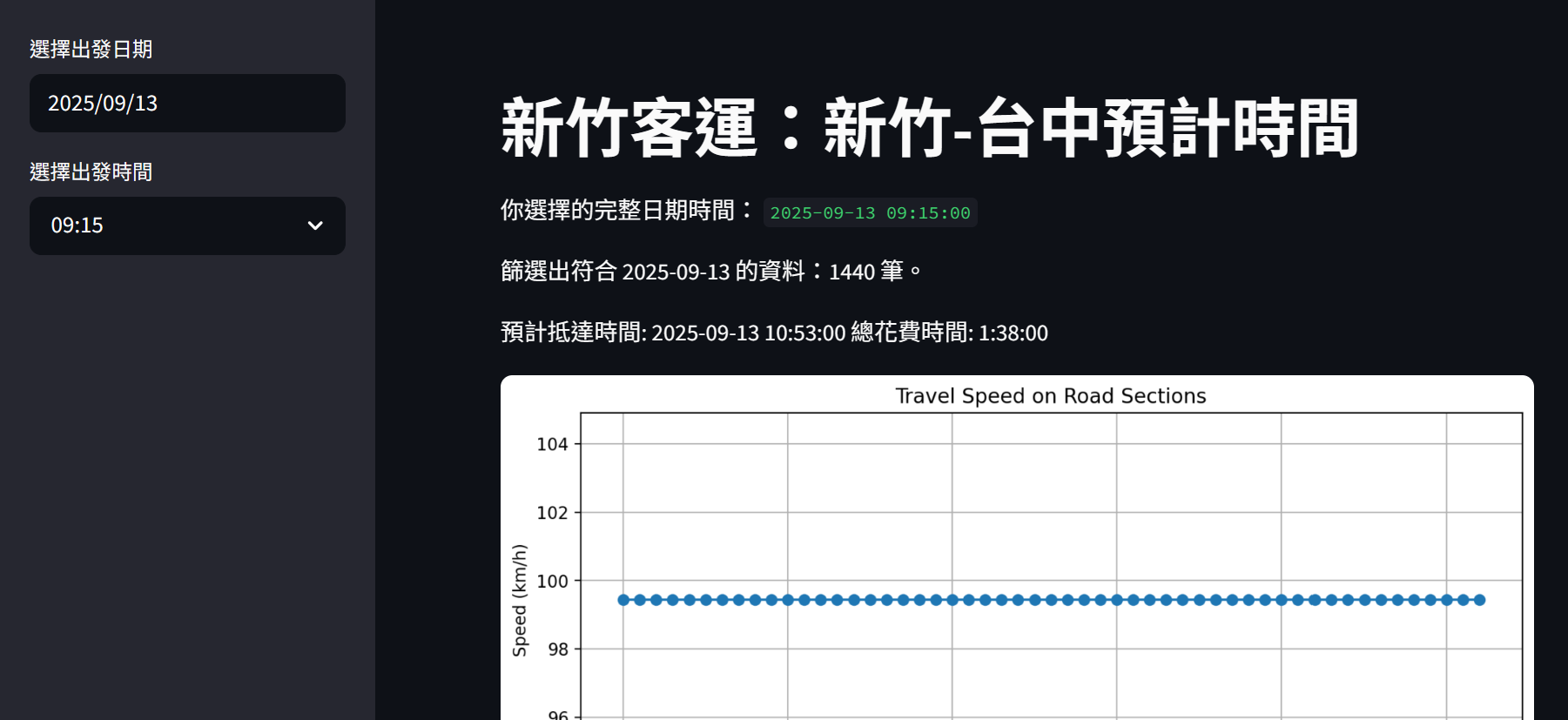
但其實好像可以直接用HTML+CSS+JavaScripts靜態網頁的架構,因為我的模型沒有包在裡面XD
正式版的 demo 網址 點此
目前覺得各方面來說有很多需要改進的地方,待會來提。
建立過程
主要流程為:
因為這次使用的資料類型為 single time series,加上懶得去找其他變量的關係,所以完全沒有做特徵工程。
資料來源簡介
我使用的欄位有:
- SectionID : 機關發布路段代碼2
- Travel_Speed :依據路況資訊蒐集起始時間至結束時間區間,計算期間所蒐集資料所得之平均旅行速度。(單位:km/h)3
選擇這個欄位的原因是因為從定義上來看,Travel_Speed 較能代表客運實際速度。
以及在檔名擷取時間。
訓練資料為 2024 年屬於國定假日範圍的資料,其中有 10 % 的資料屬於訓練階段的 valid set , 其餘 90% 為 training set;用來測試模型的 test set 為 2025年上半年國定假日範圍的資料,期間為 1/1 ~ 8/30 。
清資料
主要流程為:
將資料按2024年國定假日、符合新竹-台中的 Section 按 SectionID 爬下來
補齊遺失值,基本使用 Cubic Spline 補齊遺失值,如果補出來的資料太不合理,例如嚴重超過速限,則考慮那一天的資料都移除。所幸只有228那天有問題,只移除這一天。
最後用敘事性統計觀察資料有無異常。
訓練資料
流程:
區分 training set, valid set,test set 為2025上半年的資料。
訓練模型
計算valid set RMSE、畫圖觀察
確認OK後,拿 test set 試試
計算test set RMSE、畫圖觀察
確認都可以後再依 section 產出預測資料。
指定 LSTM 的原因
因為我想玩還有我很懶,原先在指定 LSTM 之前,有先考慮過使用 ARIMA 或是 SARIMA 模型來進行預測,不過指定這種經典的統計模型的缺點是滿吃對資料的觀察能力,我太菜了,沒有人在旁邊指導我撞牆可能會撞很久。此外,一直以來有耳聞過 LSTM 的用於 series data 的強大,也有看過一些與其他模型的預測能力比較的論文,像是這篇。
神經網路家族的模型雖然複雜,但沒有特殊的統計假設;而且 LSTM 模型適合預測沒有突發事件影響的資料,我的資料搜查範圍僅限假日,基本上沒有突發事件影響。因此考慮後決定用 LSTM 模型來進行預測。
模型架構
試了好幾個參數後,得出的最好的模型架構與效果為
class LSTMModel(nn.Module):
def __init__(self, input_size=4, hidden_layer_size=16, output_size=1, num_layers=1):
super().__init__()
self.hidden_layer_size = hidden_layer_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_layer_size, num_layers, batch_first=True)
self.linear = nn.Linear(hidden_layer_size, output_size)
def forward(self, input_seq):
batch_size = input_seq.size(0)
h0 = torch.zeros(self.num_layers, batch_size, self.hidden_layer_size).to(input_seq.device)
c0 = torch.zeros(self.num_layers, batch_size, self.hidden_layer_size).to(input_seq.device)
lstm_out, _ = self.lstm(input_seq, (h0, c0))
out = self.linear(lstm_out[:, -1, :])
return out模型參數設定
基本參數為
# 訓練參數
seq_length = 15
predict_step = 15 #一次預測15分鐘
epochs = 30
patience = 5 # early stop
# Early stopping at epoch 12.最終設定的 LSTM 模型指定參數為
LSTMModel(
(lstm): LSTM(4, 16, batch_first=True)
(linear): Linear(in_features=16, out_features=1, bias=True)
)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = LSTMModel().to(device)
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)使用的時間欄位來自擷取資料時,原始資料標記在資料夾及檔名的資訊,再分成多個欄位作為變數丟入模型裡,目前有:小時、月份、星期。
相關訓練數據
RMSE 部分 (套用到此資料集的對應單位:km/hr):
| set | RMSE |
|---|---|
| valid set | 3.0401 |
| test set | 6.0785 |
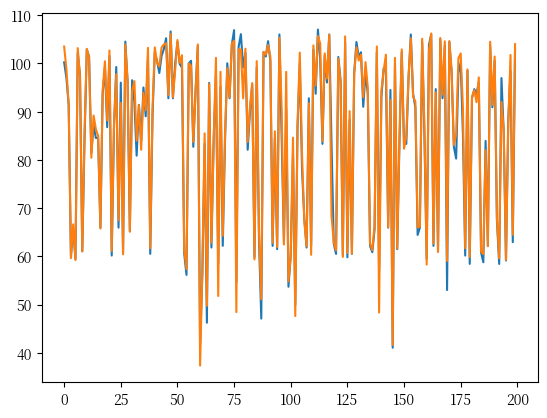 ▲ valid set 前 200 筆真實值(藍線)跟預測值(橘線)觀察圖
▲ valid set 前 200 筆真實值(藍線)跟預測值(橘線)觀察圖
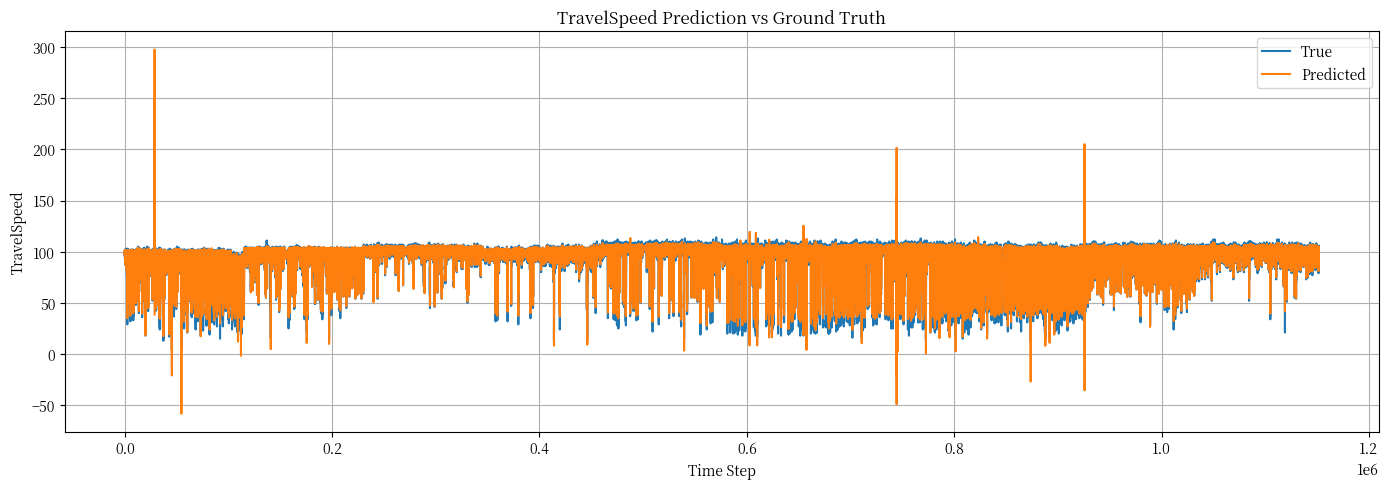 ▲ test set 真實值(藍線)跟預測值(橘線)觀察圖,可以看到除了部分超過速限的資料外,整體還行。
▲ test set 真實值(藍線)跟預測值(橘線)觀察圖,可以看到除了部分超過速限的資料外,整體還行。
無論是 valid set 還是 test set 的 RMSE 跟繪圖結果,看起來都相當不錯。換算成時間與我自己搭客運的經驗,應該只有 9 分鐘的誤差。
需要改進的地方
模型預測部分
經過一連串的調整後,目前處於觀察預測能力到底好不好用的階段。不過因為我用的 test set 只到 2025/8/30,後續的維護 & 重新訓練流程還需要再想想。此外,目前的流程為事先在本地預測好資料,再把預測好資料當成資料庫,在 Streamlit 的腳本下處理。這是因為 LSTM 預測資料需要花費很多時間,不可能讓使用者等待太久。未來可以如何調整也需要再想想。
UIUX 設計及部署
目前將資料部署在 streamlit 平台上,雖然有不用切換程式語言、使用語言直觀簡潔、不用自己重新設計 UIUX 等優點,但實際部署後網路載入速度實在是太慢了,而且 RWD 設計也很陽春。
此外,streamlit could app 會將太久沒有人造訪的網站休眠,頻率大概是超過一天就不行,對我這種使用率低的app來說不是很有利。目前背後的處理資料原理也可以用 javascrip 完成,未來用 GitHub Page 部署會更好。
無符合的項目