前言
存活分析 (Survival Analysis) 是我就讀統研所前就一直很想深入學習的科目之一,原因是它也是一門跟時間有關的一門學問。不過網路上很少人有人把它拿來跟統計學關心時間資料的代表學問-時間序列(time series)做比較,於是就來寫一篇吧!
存活分析的基本觀念
存活分析的概念雖然被廣泛應用在不同領域中,例如:生命量表(Life table)可用於保險精算;工業中的可靠度分析(Reliability)某種程度上是存活分析的非生物版本。不過這個領域主要是在醫學臨床研究下發展的,因此要了解存活分析,就要先了解學者/醫師在臨床上是怎麼調查資料,以及他們關心的是甚麼。當然,本文的企圖是從時間序列的角度切入。所以,我們從時間序列的原始資料開始。
原始資料
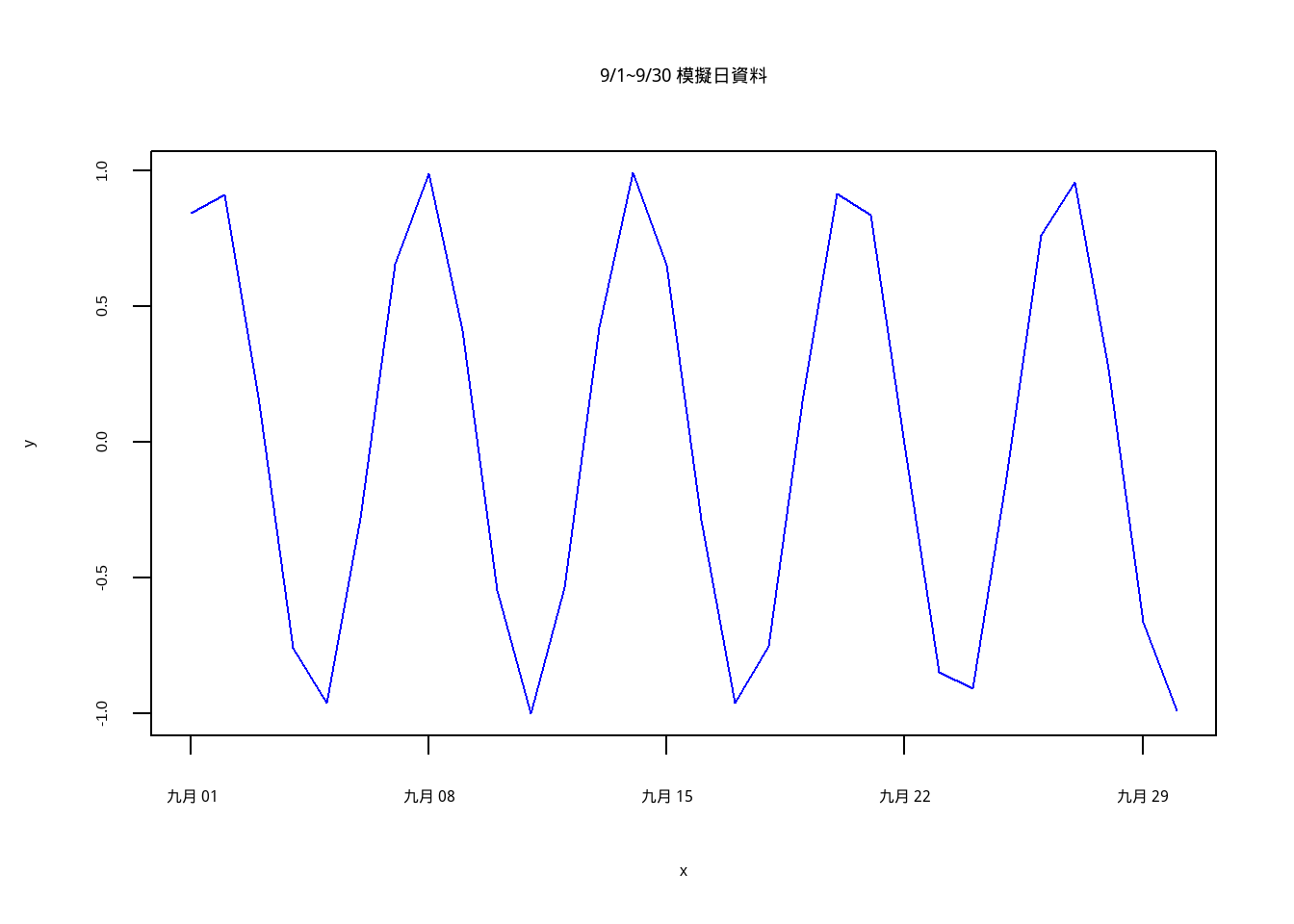
如果是時間序列,通常會是一組按時間順序排列的資料點,而研究者主要會關心下一個(或 n 個)的時間點資料會如何。因此一開始我們收集到的資料很可能會長這樣:
上圖是一個模擬9/1~9/30的資料
可以注意到我們收集的資料是一段時間的,且不管年代更久遠的資料如何,只要有足夠的樣本我們就可以分析預測下一個時間點。
第一個例子是 single time series,也有多個時間序列的例子,基本上每個 time series 的時間點一定會有對應的值:
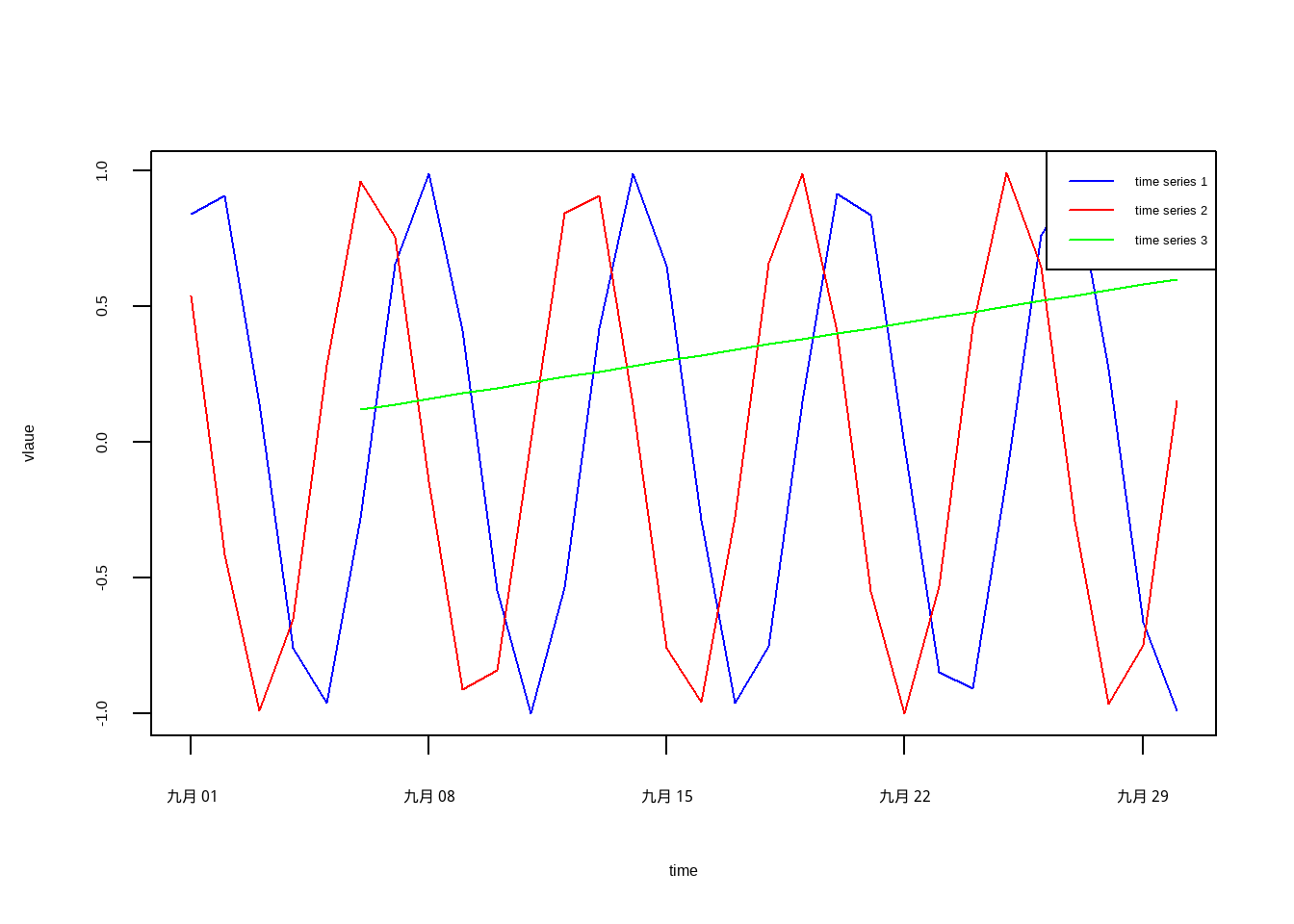
很明顯綠線是我亂畫的
若資料沒有對應值,像綠線那樣,實務上就會視為缺失值,並想辦法處理。
不過,在存活分析裡,研究者關心的問題的是每個對象的存活時間,以及為什麼對象過世,在乎的是時間的長度而非下一個時間點的值。所以原始資料會是很多條的時間序列,此外,因為對象是活體(生物),會因為各式各樣的原因離開研究,研究者沒有辦法、也不可能完整的收集到每個對象從出生到死亡經歷的時間,最多只能接收到在研究調查的期間,對象有沒有活著。所以原始資料會是這樣:
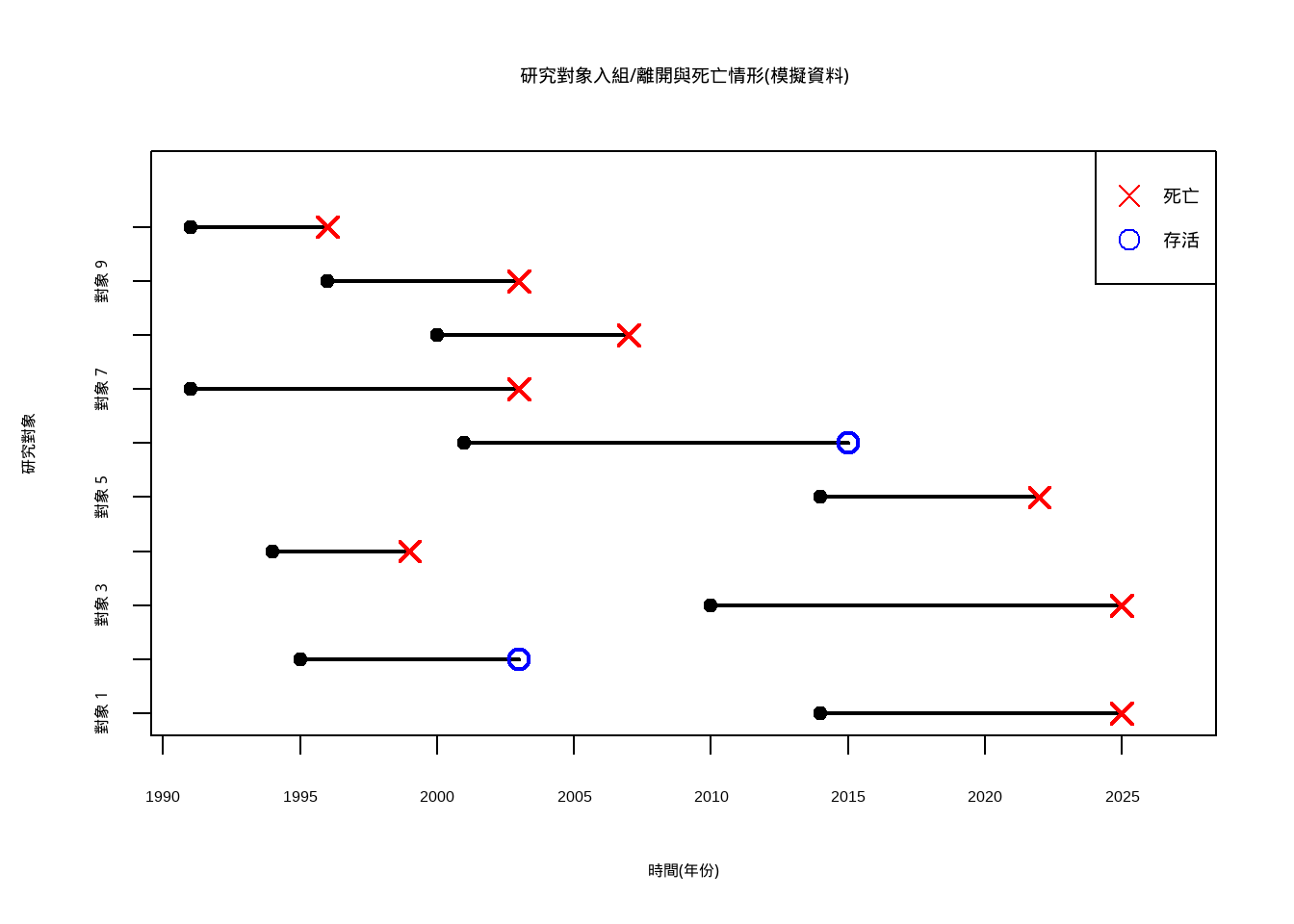
每個黑色圓圈是進入研究的時間,尾端則是標記在研究結束時對象是否存活。
這種圖示很難比較對象間的時間長度,因此會改畫成這樣:
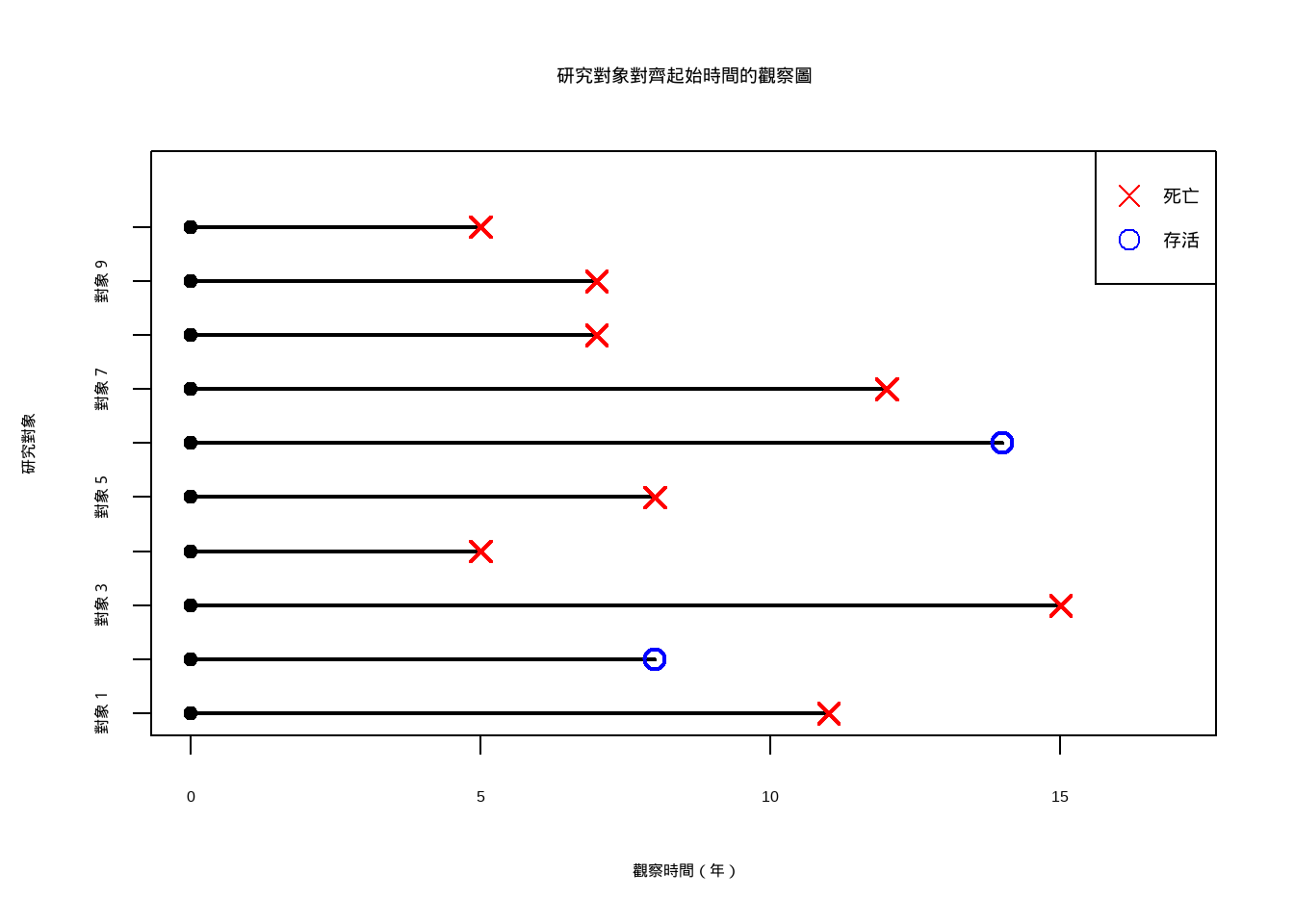
研究對象研究結束的時間,稱為病患研究時間(patient time),而對象在研究結束時仍然存活,研究者無法得知他真實過世的時間,這種資料被稱為右設限(right censor)。這是存活分析分析裡常見的資料類型。
censor 補充
讀者可能會注意到,既然有所謂的 right censor,那有沒有其他的 censor 呢?答案是有的,但要注意 censor 本來就有審查的意思在,因此這裡 censor 的定義會隨著研究者想研究的主題而改變,它代表研究者想研究卻沒有資料能證明的狀態。例如:研究者想得知不同對象的抽菸時間,需要知道他們是從甚麼時候開始抽菸及戒菸時間,但不是每個對象都能精準追蹤到甚麼時候開始抽或何時結束,這種研究者同時關心起始時間及結束時間的案例,就是 double censor。
如果不畫成圖表,則會標記成「\(\text{對象存活時間}^{\text{是否 censor}}\)」,像這樣:
\[5,5,7,7,8^{+},11,12,14^{+},15\]
其中\(+\)的意思是:對象在研究時間結束時仍存活。對應表格為:
[1] "suv_time 為存活時間"[1] "status為是否死亡,0表示研究結束時仍存活,1表示死亡" suv_time status
4 5 1
10 5 1
8 7 1
9 7 1
2 8 0
5 8 1
1 11 1
7 12 1
6 14 0
3 15 1專有名詞
時間序列的基本精神是:過去會影響現在。因此時間序列會用 \(t\) 表示時間點,lag 表示上一個時間點到下一個時間點的間隔。建模的方向也朝這個方向發展,以\(AR(1)\)舉例,它的數學式為:
Suppose \({Y_t}\) is a stationary time series , the \(AR(1)\) model is:
\(y_t = a y_{t-1} + \epsilon \quad, \, \epsilon \sim N(0,1)\)
決定要如何預測則是使用 acf (autocorrelation function ),也就是利用它們在不同 lag 下,與原本 times series 比較相似程度,進而決定如何預測。
存活分析則關心多位個體的存活時間,會用 \(T_i\) 表示每位個體的實際存活時間長度(很明顯,它是隨機變數),用\(\delta_i\)表示個體在研究其中是否死亡(這就不是隨機變數了,因為它是已知的資訊),以此發展出更多不同的專有名詞跟符號。
存活函數(Survival function)
令隨機變數 \(T\) 為時間點 0 到發生特殊事件的時間,其機率密度函數定義為 \(f(t)\),則存活函數(Survival function)表示某一位對象的存活時間超過一段時間 t 的機率,其存活函數為:
\[S(t) \equiv P(T>t) = \int_{t}^{\infty} f(t)dt\]
失敗函數
與存活函數相反的概念,也是機率密度函數的 cdf。
\[F(t)=1-S(t)\]
危險函數(Hazar function)
它的作用與存活函數類似,但它表達的是在一個時間點後死亡的機率,定義如下
\[h(t)\equiv \lim _{\Delta \to 0}\frac{P(t \leq T<t+\Delta|T\ge t)}{\Delta}\]
經過推導後可以得出:
\[h(t)=\frac{f(t)}{S(t)}=\frac{d}{dt}\log [S(t)]\]
累積危險函數(Cumulative hazar function)
就是 hazar function 的 cdf,經過推導後也可以用存活函數表示:
\[H(t)=\int_0^t h(u)du=-\log[S(t)]\]
統計推論
時間序列的統計推論的架構跟傳統統計差不多,一樣分成 Type I Error、Type II Error。主要也探討研究結論與實際有出入產生的影響。
存活分析不同,在一開始就要考慮每個對象的存活時間與在研究的時間點是否存活,還要考慮 censor 的狀況。因此把這些關心的東西用數學表示:
- \(T_i\) : 對象\(i\)的存活時間,此時確定該對象已經死亡
- \(c\) :研究開始到研究結束的時間
- \(\delta_i\) : 研究結束時是否過世/死亡
努力簡化,通常最後用兩個參數表示關心的東西:
\[U_i = \text{min}(T_i, c), \quad \delta_i=I(T_i \leq c)\]
跟傳統的統計推論相比,存活分析因為多了 censor 的概念,所以推論也圍繞 censor 打轉。
Type I Censoring
所謂的 Type I Censoring 是指每個個體的最後追蹤時間長度不同,至於為什麼會這樣前面也有提到,研究對象是活體,容易因為各種原因無法追蹤到最後(轉院、反悔退出研究…etc)。這種資料需要設定固定的 censor 時間 \(C_r\) 確保資料可以成為可用的隨機變數,即:
\[U_i = \left\{ \begin{array}{r} T_i \quad \text{if }T_i \leq C_r \\ C_r \quad \text{if }T_i > C_r \end{array} \right .\]
\(\delta_i\) 也以此類推。
Type II Censoring
Type II Censoring 的意思是在設計實驗時,以進行到第\(r\)個個體死亡時作為決定結束研究時間的基準,這種情況就不用原始的\(U_i\)而是 order statistic \(U_{(i)}\)表示收集到的資料。
\(\begin{array}{lll} U_{(1)} & = & T_{(1)} \\ U_{(2)} & = & C_{(1)} \\ \vdots & = & \vdots \\ U_{(n)} & = & T_{(r)} \end{array}\)
結論
其實與其說是跟時間序列比較,感覺更像是跟一般商管科系認知的傳統統計做比較 XD 。雖然數學推導都跳過,不過寫完對存活分析有更進一步的了解,可以前往下一篇文章邁進了~
相關文章
無符合的項目